مقدمة
لإحصاء
الإحصاء هو مجال دراسة يتعامل مع جمع البيانات وتحليلها وتفسيرها وعرضها.
يستخدم المستطلعون الذين يأخذون عينات من آرائنا بشأن موضوعات تتراوح من الفن إلى علم الحيوان منهجية إحصائية.
يتم استخدام المنهجية الإحصائية أيضًا من قبل الأعمال والصناعة للمساعدة في التحكم في جودة السلع والخدمات التي ينتجونها. يستخدم علماء الاجتماع وعلماء النفس المنهج الإحصائي لدراسة سلوكياتنا. نظرًا لنطاق تطبيقه الواسع ، لذلك دورات الإحصاء مطلوبة في تخصصات مثل علم الاجتماع وعلم النفس والعدالة الجنائية والتمريض وعلوم التمرين والصيدلة والتعليم وغيرها الكثير.
لاستيعاب هذه المجموعة المتنوعة من المستخدمين ، يتم اختيار الأمثلة والمشكلات في هذا المخطط التفصيلي من عدة مصادر مختلفة.
الإحصاء الوصفي
يُطلق على استخدام الرسوم البيانية والمخططات والجداول وحساب المقاييس الإحصائية المختلفة لتنظيم وتلخيص المعلومات الإحصاء الوصفي. تساعد الإحصائيات الوصفية في تقليل معلوماتنا إلى حجم يمكن التحكم فيه ووضعها في موضع التركيز.
مثال 1.1: تجميع متوسط الضرب ، عدد مرات الضرب ، عدد الركلات المسجلة ، وعدد الضربات على أرضيه لكل لاعب ، بالإضافة إلى متوسط الجري المكتسب ، نسبة الفوز / الخسارة ، عدد مرات الحفظ ، إلخ ،
مثال 1.2: يقدم المنشور المعنون "الجريمة في الولايات المتحدة" والذي نشره مكتب التحقيقات الفيدرالي معلومات موجزة عن الجرائم المختلفة في الولايات المتحدة.
المقاييس الإحصائية الواردة في هذا المنشور هي أيضًا أمثلة للإحصاءات الوصفية وهي مفيدة للأفراد في تطبيق القانون.
الإحصاءات الاستنتاجية: السكان والعينة
السكان هي المجموعة الكاملة للأفراد أو العناصر أو البيانات قيد الدراسة في دراسة إحصائية.
يسمى جزء السكان المختار للتحليل بالعينة." استنتاجي"
تتكون الإحصائيات من تقنيات للوصول إلى استنتاجات حول السكان بناءً على المعلومات الواردة في العينة.
مثال 1.3 يتم نشر نتائج استطلاعات الرأي على نطاق واسع في كل من وسائل الإعلام المكتوبة والإلكترونية.
يستخدم منظمو الاستطلاعات تقنيات الإحصاء الاستدلالي على نطاق واسع. يقدم الجدول 1.1 عدة أمثلة على السكان والعينات التي تمت مواجهتها في استطلاعات الرأي التي نشرتها وسائل الإعلام. تُستخدم طرق الإحصاء الاستدلالي لعمل استنتاجات حول السكان بناءً على النتائج الموجودة في العينات ولإعطاء مؤشر حول موثوقية هذه الاستنتاجات. لنفترض أن نتائج استطلاع لـ 600 ناخب مسجل تم الإبلاغ عنها على النحو التالي: 40 بالمائة من الناخبين يوافقون على سياسات الرئيس الاقتصادية. وبلغت نسبة الخطأ في الاستطلاع 4٪. يشير الاستطلاع إلى أن ما يقدر بنحو 40٪ من جميع الناخبين المسجلين يوافقون على السياسات الاقتصادية ، لكنها قد تصل إلى 36٪ أو تصل إلى 44٪.

مثال 1.4 يتم تطبيق تقنيات الإحصاء الاستدلالي في العديد من العمليات الصناعية للتحكم في جودة المنتجات المنتجة. في البيئات الصناعية ، قد تتكون قائمة السكان من الإنتاج اليومي لفرش الأسنان ورقائق الكمبيوتر والمسامير وما إلى ذلك. ستتألف العينة من اختيار عشوائي وتمثيلي للعناصر من عملية إنتاج فرش الأسنان ، ورقائق الكمبيوتر ، والمسامير ، إلخ. تُستخدم المعلومات الواردة في العينات اليومية لإنشاء مخططات التحكم. ثم يتم استخدام مخططات التحكم لمراقبة جودة المنتجات.
مثال 1.5 تستخدم الطرق الإحصائية للإحصاءات الاستنتاجية لتحليل البيانات التي تم جمعها في الدراسات البحثية. يعطي الجدول 1.2 العينات والسكان للعديد من هذه الدراسات. يتم استخدام المعلومات الواردة في العينات لعمل استنتاجات تتعلق بالسكان. إذا وجد أن 245 من 350 أو 70٪ من نزلاء السجون في دراسة عدالة جنائية تعرضوا لسوء المعاملة وهم أطفال ، فما هي الاستنتاجات التي يمكن استنتاجها فيما يتعلق بنسبة جميع نزلاء السجون الذين تعرضوا للإيذاء وهم أطفال؟

مجموعة متغيرة وملاحظة وبيانات
المتغير هو سمة من سمات الاهتمام فيما يتعلق بالعناصر الفردية لمجتمع أو عينة. غالبًا ما يتم تمثيل المتغير بحرف مثل x أو y أو z. تسمى قيمة المتغير لعنصر معين واحد من العينة أو المجتمع بالملاحظة. تتكون مجموعة البيانات من ملاحظات متغيرات لعناصر العينة.
مثال 1.6 يتم استقصاء ستمائة ناخب مسجل وسؤال كل واحد عما إذا كانوا يوافقون أو لا يوافقون على السياسات الاقتصادية للرئيس. المتغير هو رأي الناخب المسجل في السياسات الاقتصادية للرئيس. تتكون مجموعة البيانات من 600 ملاحظة. ستكون كل ملاحظة استجابة "الموافقة" أو
الرد "لا توافق". إذا تم ترميز الاستجابة "الموافقة" على أنها الرقم 1 وتم ترميز الاستجابة "عدم الموافقة" بالرقم 0 ، فستتألف مجموعة البيانات من 600 ملاحظة ، كل واحدة منها إما 0 أو 1. إذا تم استخدام x لـ تمثل المتغير ، ثم يمكن أن تفترض x قيمتين ، 0 أو 1.
مثال 1.7 تم إجراء دراسة استقصائية على 2500 أسرة يرأسها أحد الوالدين وتتمثل إحدى سمات الاهتمام في الدخل السنوي للأسرة. تتكون مجموعة البيانات من دخل الأسرة السنوي البالغ 2500 فرد للأفراد في المسح. إذا تم استخدام y لتمثيل المتغير ، فستكون قيم y بين أصغر وأكبر دخل سنوي للأسرة لـ 2500 أسرة.
مثال 1.8: تم تسجيل عدد مخالفات السرعة الصادرة عن 75 من شرطة مرور ولاية نبراسكا لشهر يونيو. تتكون مجموعة البيانات من 75 ملاحظة
متغير كمي: متغير ومتغير مستمر
يتم تحديد المتغير الكمي عندما ينتج عن وصف الخاصية محل الاهتمام قيمة عددية. عندما يكون القياس مطلوبًا لوصف خاصية الاهتمام أو أنه من الضروري إجراء عد لوصف الخاصية ، يتم تحديد متغير كمي. المتغير المنفصل هو متغير كمي قيمه قابلة للعد. المتغيرات المنفصلة عادة
نتيجة العد. المتغير المستمر هو متغير كمي يمكن أن يفترض أي قيمة عددية على مدى فترة أو على فترات متعددة. عادة ما ينتج المتغير المستمر عن إجراء قياس من نوع ما.
مثال 1.9 يعطي الجدول 1.3 العديد من المتغيرات المنفصلة ومجموعة القيم الممكنة لكل منها. في كل حالة يتم تحديد قيمة المتغير عن طريق العد. بالنسبة لعلبة تحتوي على 100 حقنة لمرضى السكري ، يتم تحديد عدد الإبر المعيبة من خلال حساب عدد الإبر المعيبة من بين الـ 100 حقنة. يجب أن يساوي عدد العيوب التي تم العثور عليها إحدى القيم المدرجة البالغ عددها 101. عدد النتائج المحتملة محدود لكل من المتغيرات الأربعة الأولى ؛ أي أن عدد النتائج المحتملة هو 101 و 31 و 501 و 51 على التوالي. عدد النتائج المحتملة للمتغير الأخير لا نهائي. نظرًا لأن عدد النتائج المحتملة غير محدود ويمكن عده بالنسبة لهذا المتغير ، فإننا نقول إن عدد النتائج غير محدود إلى حد كبير.

في بعض الأحيان ليس من الواضح ما إذا كان المتغير منفصلاً أم مستمرًا. يتم التعبير عن درجات الاختبار كنسبة مئوية ، على سبيل المثال ، عادةً كأعداد صحيحة بين 0 و 100. من الممكن إعطاء درجة مثل 75.57565. ومع ذلك ، لا يقوم المعلمون بذلك في الممارسة العملية لأنهم غير قادرين على التقييم لهذه الدرجة من الدقة. يُنظر إلى هذا المتغير عادةً على أنه مستمر ، على الرغم من أنه منفصل لجميع الأغراض العملية. للتلخيص ، نظرًا لقيود القياس ، تفترض العديد من المتغيرات المستمرة في الواقع عددًا قابلاً للعد من القيم.
مثال 1.10 يعطي الجدول 1.4 العديد من المتغيرات المستمرة ومجموعة القيم الممكنة لكل منها. جميع المتغيرات الثلاثة المستمرة الواردة في الجدول 1.4 تتضمن القياس ، في حين أن المتغيرات في المثال 1.9 تتضمن جميعها العد.
متغير نوعي
يتم تحديد المتغير النوعي عندما ينتج عن وصف الخاصية محل الاهتمام قيمة غير رقمية. يمكن تصنيف المتغير النوعي إلى فئتين أو أكثر.
مثال 1.11 يقدم الجدول 1.5 العديد من الأمثلة على المتغيرات النوعية إلى جانب مجموعة من الفئات التي يمكن تصنيفها إليها.
غالبًا ما يتم ترميز الفئات المحتملة للمتغيرات النوعية لغرض إجراء تحليل إحصائي محوسب. يمكن ترميز الحالة الاجتماعية على أنها 1 أو 2 أو 3 أو 4 ، حيث يمثل 1 أعزب ، و 2 يمثل متزوجًا ، و 3 يمثل مطلقًا ، و 4 يمثل منفصلًا. الجنس المتغير يمكن ترميزه على أنه 0 للإناث و 1 للذكور. يمكن ترميز فئات أي متغير نوعي بطريقة مماثلة. على الرغم من أن القيم العددية مرتبطة بخاصية الاهتمام بعد تشفيرها ، فإن المتغير يعتبر متغيرًا نوعيًا.
المستويات الاسمية والعادية والمتداخلة والنسبية للقياس
يمكن تصنيف البيانات إلى أربعة مستويات للقياس أو جداول القياسات. ينطبق المقياس الاسمي على البيانات المستخدمة لتحديد الفئة. يتميز المستوى الاسمي للقياس ببيانات تتكون من أسماء أو تسميات أو فئات فقط. لا يمكن ترتيب بيانات المقياس الاسمي في مخطط ترتيب. لا يتم إجراء العمليات الحسابية للجمع والطرح والضرب والقسمة للبيانات الاسمية.
مثال 1.12 يعطي الجدول 1.6 العديد من المتغيرات النوعية ومجموعة من قيم بيانات المستوى الاسمي الممكنة. غالبًا ما يتم تشفير قيم البيانات للتسجيل في ملف بيانات الكمبيوتر. يمكن تسجيل فصيلة الدم على أنها 1 أو 2 أو 3 أو 4 ؛ يمكن تسجيل حالة الإقامة على أنها 1 ، 2 ،. . . ، أو 50 ؛ ونوع الجريمة يمكن تسجيلها على أنها 0 أو 1 ، أو 1 أو 2 ، إلخ. وبالمثل ، يمكن تسجيل لون علامة الطريق على أنه 1 أو 2 أو 3 أو 4 أو 5 ويمكن تسجيل الدين على أنه 1 أو 2 أو 3. لا يوجد ترتيب مرتبط بهذه البيانات ولا يتم تنفيذ العمليات الحسابية. على سبيل المثال ، إضافة "مسيحي ومسلم" (1 + 2) ولا يعطي الاديان الاخرى (3).

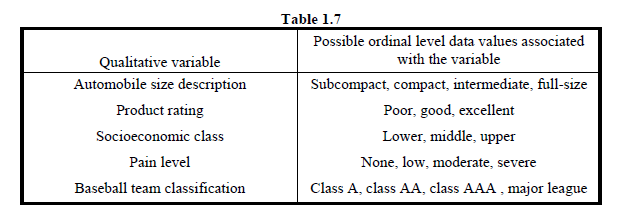
ينطبق المقياس الترتيبي على البيانات التي يمكن ترتيبها بترتيب ما ، لكن الاختلافات بين قيم البيانات إما لا يمكن تحديدها أو لا معنى لها. يتميز المستوى الترتيبي للقياس بالبيانات التي تنطبق على الفئات التي يمكن تصنيفها. يمكن ترتيب بيانات المقياس الترتيبي في مخطط ترتيب.
مثال 1.13 يعطي الجدول 1.7 العديد من المتغيرات النوعية ومجموعة من قيم بيانات المستوى الترتيبي الممكنة. غالبًا ما يتم تشفير قيم البيانات لبيانات المستوى الترتيبي لتضمينها في ملفات بيانات الكمبيوتر. لا يتم تنفيذ العمليات الحسابية على بيانات المستوى الترتيبي ، ولكن يوجد مخطط ترتيب. السيارة ذات الحجم الكامل أكبر من الحجم الصغير ، والإطار المصنف ممتازًا أفضل من الإطار المصنف على أنه ضعيف ، ولا يوجد ألم أفضل من أي مستوى من الألم ، ومستوى اللعب في دوري البيسبول الرئيسي أفضل من مستوى اللعب في فئة AA ، وهكذا دواليك.
ينطبق مقياس الفاصل الزمني على البيانات التي يمكن ترتيبها بترتيب ما والتي تكون الاختلافات في قيم البيانات ذات مغزى لها. ينتج المستوى الفاصل للقياس عن العد أو القياس. يمكن ترتيب بيانات مقياس nterval في مخطط ترتيب ويمكن حساب الاختلافات وتفسيرها. يتم اختيار القيمة صفر بشكل تعسفي لبيانات الفاصل الزمني ولا تعني عدم وجود الخاصية التي يتم قياسها. النسب ليست ذات مغزى لبيانات الفاصل الزمني.
مثال 1.14 تمثل درجات Stanford-Binet IQ بيانات مستوى الفاصل الزمني. درجة ذكاء جو تساوي 100 ودرجة ذكاء جون تساوي 150. يمتلك جون معدل ذكاء أعلى من جو ؛ أي أنه يمكن ترتيب درجات معدل الذكاء بالترتيب. درجة ذكاء جون أعلى بمقدار 50 نقطة من درجة ذكاء جو ؛ أي أنه يمكن حساب الاختلافات وتفسيرها. ومع ذلك ، لا يمكننا أن نستنتج أن جون 1.5 مرة (150/100 = 1.5) أكثر ذكاءً من جو. درجة حاصل الذكاء صفر لا تشير إلى نقص كامل في الذكاء.
مثال 1.15 تمثل درجات الحرارة بيانات مستوى الفاصل الزمني. بلغت درجة الحرارة المرتفعة في 1 فبراير 25 درجة فهرنهايت وكانت درجة الحرارة المرتفعة في 1 مارس تعادل 50 درجة فهرنهايت. كان الجو أكثر دفئًا في 1 مارس مما كان عليه في الأول من فبراير. أي أنه يمكن ترتيب درجات الحرارة بالترتيب. كانت درجة الحرارة أعلى بمقدار 25 درجة مئوية في الأول من آذار (مارس) عنها في الأول من شباط (فبراير). أي يمكن حساب الاختلافات وتفسيرها. لا يمكننا أن نستنتج أنه كان أكثر دفئًا في الأول من آذار (مارس) مرتين مما كان عليه في الأول من شباط (فبراير). أي أن النسب غير قابلة للتفسير بسهولة. لا تشير درجة حرارة 0 درجة فهرنهايت إلى غياب الدفء.
مثال 1.16 تمثل درجات الاختبار بيانات مستوى الفاصل الزمني. سجلت لانا 80 في الاختبار وسجل كريستين 40 في الاختبار. سجلت لانا أعلى من كريستين في الاختبار ؛ أي أنه يمكن ترتيب درجات الاختبار بالترتيب. سجلت لانا 40 نقطة أعلى من كريستين في الاختبار ؛ أي أنه يمكن حساب الاختلافات وتفسيرها. لا يمكننا أن نستنتج أن لانا تعرف ضعف معرفة كريستين بالموضوع. لا تشير درجة الاختبار 0 إلى عدم وجود معرفة بشأن الموضوع. مقياس النسبة ينطبق على البيانات التي يمكن تصنيفها والتي يمكن إجراء جميع العمليات الحسابية بما في ذلك القسمة. القسمة على الصفر ، بالطبع ، مستبعدة. ينتج مستوى النسبة للقياس عن العد أو القياس. يمكن ترتيب بيانات مقياس النسبة في مخطط ترتيب ويمكن حساب الفروق والنسب وتفسيرها. تحتوي بيانات مستوى النسبة على صفر مطلق وتشير القيمة الصفرية إلى الغياب التام لخاصية الفائدة.
مثال 1.17 إن جرامات الدهون المستهلكة يوميًا للبالغين في الولايات المتحدة هي بيانات مقياس النسبة. يستهلك جو 50 جرامًا من الدهون يوميًا ، ويستهلك جون 25 جرامًا يوميًا. يستهلك جو ضعف كمية الدهون التي يستهلكها جون يوميًا ، نظرًا لأن 50/25 = 2. بالنسبة للفرد الذي يستهلك 0 جرامًا من الدهون في يوم معين ، هناك غياب تام للدهون المستهلكة في ذلك اليوم. لاحظ أن النسبة قابلة للتفسير وأن الصفر المطلق موجود.
ملاحظة التلخيص
تتضمن العديد من المقاييس الإحصائية قيم مختلفة. لنفترض أن عدد مكالمات الطوارئ 911 التي تم تلقيها في أربعة أيام كان 411 ، و 375 ، و 400 ، و 478. إذا سمحنا أن يمثل x عدد المكالمات المستلمة يوميًا ، فسيتم تمثيل قيم المتغير للأيام الأربعة على النحو التالي: x1 = 411 ، x2 = 375 ، x3 = 400 ، و x4 = 478. يتم تمثيل مجموع المكالمات للأيام الأربعة على النحو x1 + x2 + x3 + x4 ، وهو ما يساوي 411 + 375 + 400 + 478 أو 1664. الرمز Σx ، تُقرأ على أنها "مجموع x" ، تُستخدم لتمثيل x1 + x2 + x3 + x4. الحرف اليوناني الكبير Σ (يُنطق سيجما) يتوافق مع الحرف الإنجليزي S ويرمز إلى العبارة "مجموع." باستخدام تدوين الجمع ، سيتم كتابة العدد الإجمالي لـ 911 مكالمة للأيام الأربعة كـ Σx = 1664.
مثال 1.19 تم ملاحظة القيم الخمس التالية للمتغير
x: x1 = 4، x2 = 5، x3 = 0، x4 = 6، x5 = 10.
توضح الحسابات التالية استخدام تدوين الجمع.
Σx = x1 + x2 + x3 + x4 + x5 = 4 + 5 + 0 + 6 + 10 = 25
(Σx)2 = (x1 + x2 + x3 + x4 + x5 )2 = (25)2 = 625
Σx2 = x1
2
+ x2
2 + x3
2 + x4
2 + x5
2 = 42 + 52 + 02 + 62 + 102 = 177
Σ(x – 5) = (x1 – 5) + (x2 – 5) + (x3 – 5) + (x4 – 5) + (x5 – 5)
Σ(x – 5) = ( 4 – 5 ) + ( 5 – 5 ) + ( 0 – 5 ) + ( 6 – 5 ) + ( 10 – 5) = –1 + 0 – 5 + 1 + 5 = 0
مثال 1.20 استخدم ورقة عمل EXCEL لإجراء العمليات التالية على المتغيرات التالية.
Σx، Σx2، Σy، y2، Σyx.

في الشكل 1-1 ، تم إدخال قيم المتغير x في A2: A11 ، وتم إدخال قيم المتغير y في B2: B11 ، وتم إدخال التعبير = A2 ^ 2 في C2. قم بإجراء النقر والسحب من C2 إلى C11. يتم إدخال التعبير = B ^ 2 في D2 ويتم إجراء النقر والسحب من D2 إلى D11 ، ويتم إدخال التعبير = A2 * B2 في E2. قم بإجراء النقر والسحب من E2 إلى E11. (انظر الشكل 1-1.) الصيغة ، = SUM (A2: A11) في A12 تعطي Σx ، الصيغة ، = SUM (B2: B11) في B12 تعطي Σy ، الصيغة ، = SUM (C2: C11) في يعطي C12 Σx2 ، الصيغة ،
= SUM (D2: D11) في D12 تعطي Σy2 ، والصيغة = SUM (E2: E11) في E12 تعطي Σxy. كبديل لإدخال صيغ منفصلة في كل خلية ، يمكنك أيضًا تحديد الخلايا A12: E12 ثم النقر فوق الزر للحصول على جميع القيم دفعة واحدة.
شكل 1-1 EXCEL ورقة عمل توضح حسابات المجاميع ومجموع المربعات ومجموع النواتج المتقاطعة
برامج الكمبيوتر والإحصائيات
تتضمن تقنيات الإحصاء الوصفي والاستنتاجي حسابات متكررة مطولة بالإضافة إلى بناء تراكيب رسومية مختلفة. تم تبسيط هذه الحسابات والإنشاءات الرسومية من خلال تطوير برامج الكمبيوتر الإحصائية. يشار إلى برامج الكمبيوتر هذه باسم حزم البرامج الإحصائية ، أو مجرد حزم إحصائية. هذه الحزم الإحصائية عبارة عن برامج كمبيوتر كبيرة تؤدي العمليات الحسابية المختلفة والإنشاءات الرسومية التي تمت مناقشتها في هذا المخطط بالإضافة إلى العديد من البرامج الأخرى خارج نطاق المخطط التفصيلي. الحزم الإحصائية متاحة حاليًا للاستخدام على الحواسيب الكبيرة ، وأجهزة الكمبيوتر الصغيرة ، وأجهزة الكمبيوتر الصغيرة. يوجد حاليا العديد من الحزم الإحصائية المتاحة. مثل: SAS و SPSS و MINITAB و EXCEL و STATISTIX. يحتاج طالب الإحصاء إلى أن يكون قادرًا على قراءة مخرجات الحزم المختلفة وكذلك استخدام الحزم.











{kind=link}
تعليقات
إرسال تعليق
شاركنا الآراء ،،